VoxCPM: Tokenizer-Free TTS for Expressive Multilingual Speech Generation, Voice Design, and True-to-Life Cloning





👋 Contact us on Feishu | WeChat
---
## Contents
- [Overview](#overview)
- [Introduction](#introduction)
- [Highlights](#-highlights)
- [News](#news)
- [Performance](#-performance)
- [Quick Start](#-quick-start)
- [Installation](#installation)
- [Python API](#python-api)
- [Text-to-Speech](#%EF%B8%8F-text-to-speech)
- [Voice Design](#-voice-design)
- [Voice Cloning](#-voice-cloning)
- [Style Control](#-style-control)
- [CLI Usage](#cli-usage)
- [Web Demo](#web-demo)
- [Models & Versions](#-models--versions)
- [Architecture](#-architecture)
- [Fine-tuning](#%EF%B8%8F-fine-tuning)
- [Documentation](#-documentation)
- [Ecosystem & Community](#-ecosystem--community)
- [Risks and Limitations](#%EF%B8%8F-risks-and-limitations)
- [Citation](#-citation)
---
## Overview
### Introduction
VoxCPM is a **tokenizer-free** Text-to-Speech system that directly generates continuous speech representations via an end-to-end **diffusion autoregressive architecture**, bypassing discrete tokenization to achieve highly natural and expressive synthesis.
**VoxCPM 2** is the latest major release — a **2.3B** parameter model trained on **2.36 million hours** of multilingual data, now supporting **30 languages**, **Voice Design**, **Style Control**, and native **48kHz** studio-quality audio output. Built on a [MiniCPM-4](https://github.com/OpenBMB/MiniCPM) backbone.
### ✨ Highlights
- 🌍 **30-Language Multilingual** — Input text in any of the 30 supported languages and synthesize directly, no language tag needed
- 🎨 **Voice Design** — Create a voice from scratch via natural-language description, without any reference audio
- 🎭 **Style Control** — Control speaking style (emotion, pace, etc.) of a cloned voice through text tags
- 🎤 **Zero-Shot Voice Cloning** — Clone any voice from a short reference clip with high fidelity
- 🔊 **48kHz Native Audio** — Redesigned AudioVAE V2 with asymmetric encode/decode for studio-quality output
- 🧠 **Context-Aware Synthesis** — Automatically infers appropriate prosody and expressiveness from text content
- ⚡ **Real-Time Streaming** — RTF as low as ~0.15 on NVIDIA RTX 4090
🌍 Supported Languages (30)
Arabic, Burmese, Chinese, Danish, Dutch, English, Finnish, French, German, Greek, Hebrew, Hindi, Indonesian, Italian, Japanese, Khmer, Korean, Lao, Malay, Norwegian, Polish, Portuguese, Russian, Spanish, Swahili, Swedish, Tagalog, Thai, Turkish, Vietnamese
### News
* **[2026.04]** 🔥 We release **VoxCPM 2** — 2.3B, 30 languages, Voice Design & Style Control, 48kHz audio! [Weights](https://huggingface.co/openbmb/VoxCPM2) | [Docs](https://voxcpm.readthedocs.io/en/dev_2.0/)
* **[2025.12]** 🎉 Open-source **VoxCPM1.5** [weights](https://huggingface.co/openbmb/VoxCPM1.5) with SFT & LoRA fine-tuning. (**🏆 #1 GitHub Trending**)
* **[2025.09]** 🔥 Release VoxCPM [Technical Report](https://arxiv.org/abs/2509.24650).
* **[2025.09]** 🎉 Open-source **VoxCPM-0.5B** [weights](https://huggingface.co/openbmb/VoxCPM-0.5B) & [Playground](https://huggingface.co/spaces/OpenBMB/VoxCPM-Demo). (**🏆 #1 HuggingFace Trending**)
---
## 📊 Performance
VoxCPM achieves state-of-the-art results on public zero-shot TTS benchmarks. VoxCPM 2 results are coming soon — below are VoxCPM-0.5B results. See [full benchmarks](docs/performance.md) for details.
**Seed-TTS-eval**
| Model | Params | Open | EN WER%⬇ | EN SIM%⬆ | ZH CER%⬇ | ZH SIM%⬆ |
|---|:---:|:---:|:---:|:---:|:---:|:---:|
| CosyVoice2 | 0.5B | ✅ | 3.09 | 65.9 | 1.38 | 75.7 |
| F5-TTS | 0.3B | ✅ | 2.00 | 67.0 | 1.53 | 76.0 |
| IndexTTS2 | 1.5B | ✅ | 2.23 | 70.6 | 1.03 | 76.5 |
| DiTAR | 0.6B | ❌ | 1.69 | 73.5 | 1.02 | 75.3 |
| Seed-TTS | — | ❌ | 2.25 | 76.2 | 1.12 | 79.6 |
| **VoxCPM-0.5B** | **0.5B** | **✅** | **1.85** | **72.9** | **0.93** | **77.2** |
| **VoxCPM 2** | **2.3B** | **✅** | *coming soon* | | | |
**CV3-eval**
| Model | ZH CER%⬇ | EN WER%⬇ | Hard-ZH CER%⬇ | Hard-EN WER%⬇ |
|---|:---:|:---:|:---:|:---:|
| CosyVoice2 | 4.08 | 6.32 | 12.58 | 11.96 |
| IndexTTS2 | 3.58 | 4.45 | 12.8 | 8.78 |
| CosyVoice3-0.5B | 3.89 | 5.24 | 14.15 | 9.04 |
| **VoxCPM-0.5B** | **3.40** | **4.04** | 12.9 | **7.89** |
| **VoxCPM 2** | *coming soon* | | | |
---
## 🚀 Quick Start
### Installation
```sh
pip install voxcpm
```
> **Requirements:** Python ≥ 3.10, PyTorch ≥ 2.5.0, CUDA ≥ 12.0. See [Quick Start Docs](https://voxcpm.readthedocs.io/en/dev_2.0/quickstart.html) for details.
### Python API
#### 🗣️ Text-to-Speech
```python
from voxcpm import VoxCPM
import soundfile as sf
model = VoxCPM.from_pretrained("openbmb/VoxCPM2")
wav = model.generate(
text="VoxCPM 2 brings multilingual support, voice design, and studio-quality audio.",
cfg_value=2.0,
inference_timesteps=10,
)
sf.write("output.wav", wav, 48000)
```
#### 🎨 Voice Design
Create a voice from a natural-language description — no reference audio needed:
```python
wav = model.generate(
text="(A warm, gentle female voice in her 30s with a calm and soothing tone) "
"Welcome to VoxCPM 2, the next generation of realistic speech synthesis.",
)
sf.write("voice_design.wav", wav, 48000)
```
#### 🎤 Voice Cloning
Clone any voice from a short reference clip:
```python
wav = model.generate(
text="This is a voice cloning demonstration using VoxCPM 2.",
reference_wav_path="speaker_reference.wav",
)
sf.write("cloned.wav", wav, 48000)
```
#### 🎭 Style Control
Clone a voice while controlling speaking style with a text tag:
```python
wav = model.generate(
text="(Speaking slowly with a whispering, mysterious tone) "
"The secret lies hidden in the ancient library, waiting to be discovered.",
reference_wav_path="speaker_reference.wav",
)
sf.write("style_control.wav", wav, 48000)
```
🔄 Streaming API
```python
import numpy as np
chunks = []
for chunk in model.generate_streaming(
text="Streaming text to speech is easy with VoxCPM!",
):
chunks.append(chunk)
wav = np.concatenate(chunks)
sf.write("streaming.wav", wav, 48000)
```
### CLI Usage
```bash
# Voice design (no reference audio needed)
voxcpm design \
--text "VoxCPM 2 brings studio-quality multilingual speech synthesis." \
--output out.wav
# Voice design with style control
voxcpm design \
--text "VoxCPM 2 brings studio-quality multilingual speech synthesis." \
--control "Young female voice, warm and gentle, slightly smiling" \
--output out.wav
# Voice cloning (reference audio)
voxcpm clone \
--text "This is a voice cloning demo." \
--reference-audio path/to/voice.wav \
--output out.wav
# Hi-Fi cloning (prompt audio + transcript)
voxcpm clone \
--text "This is a voice cloning demo." \
--prompt-audio path/to/voice.wav \
--prompt-text "reference transcript" \
--output out.wav
# Batch processing
voxcpm batch --input examples/input.txt --output-dir outs
# Help
voxcpm --help
```
### Web Demo
```bash
python app.py # then open http://localhost:7860
```
> **Full parameter reference, multi-scenario examples, and voice cloning tips →** [Quick Start Guide](https://voxcpm.readthedocs.io/en/dev_2.0/quickstart.html) | [Usage Guide & Best Practices](https://voxcpm.readthedocs.io/en/dev_2.0/chefsguide.html)
---
## 📦 Models & Versions
| | **VoxCPM 2** | **VoxCPM 1.5** | **VoxCPM-0.5B** |
|---|:---:|:---:|:---:|
| **Status** | 🟢 Latest | Stable | Legacy |
| **Parameters** | 2.3B | 800M | 640M |
| **Audio Sample Rate** | 48kHz | 44.1kHz | 16kHz |
| **LM Token Rate** | 6.25Hz | 6.25Hz | 12.5Hz |
| **Languages** | 30 | 2 (zh, en) | 2 (zh, en) |
| **Voice Design** | ✅ | — | — |
| **Style Control** | ✅ | — | — |
| **Reference Cloning** | ✅ Isolated & Continuation | Continuation only | Continuation only |
| **SFT / LoRA** | ✅ | ✅ | ✅ |
| **RTF (RTX 4090)** | ~0.15 | ~0.15 | 0.17 |
| **Weights** | [🤗 HF](https://huggingface.co/openbmb/VoxCPM2) / [MS](https://modelscope.cn/models/OpenBMB/VoxCPM2) | [🤗 HF](https://huggingface.co/openbmb/VoxCPM1.5) / [MS](https://modelscope.cn/models/OpenBMB/VoxCPM1.5) | [🤗 HF](https://huggingface.co/openbmb/VoxCPM-0.5B) / [MS](https://modelscope.cn/models/OpenBMB/VoxCPM-0.5B) |
| **Technical Report** | Coming soon | — | [arXiv](https://arxiv.org/abs/2509.24650) |
| **Demo Page** | Coming soon | — | [Audio Samples](https://openbmb.github.io/VoxCPM-demopage) |
> See the full [Model & Version History](https://voxcpm.readthedocs.io/en/dev_2.0/models.html) for architecture comparison and migration guide.
---
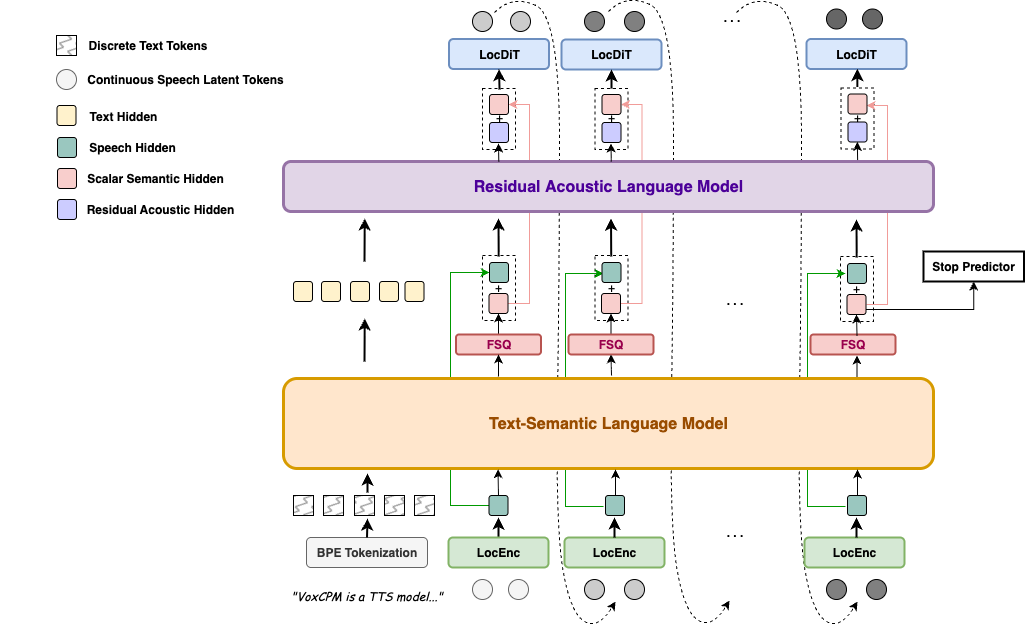
## 🏗️ Architecture
VoxCPM adopts a **tokenizer-free, diffusion autoregressive** architecture that models speech in continuous latent space rather than discrete tokens. The system consists of a four-stage pipeline:
1. **Local Encoder** — Encodes input audio patches into compact local representations
2. **Text-Semantic LM** — A causal language model (based on [MiniCPM-4](https://github.com/OpenBMB/MiniCPM)) that jointly processes text tokens and audio embeddings to capture high-level semantic intent
3. **Residual Acoustic LM** — Fuses semantic-level and acoustic-level information through concat-projection to model fine-grained acoustic details
4. **Local DiT (CFM)** — A Conditional Flow Matching diffusion transformer that generates continuous audio latents conditioned on the LM outputs, producing high-fidelity speech patches
The generated latents are decoded by **AudioVAE** into waveforms. VoxCPM 2 uses AudioVAE V2 with asymmetric encode/decode design (16kHz encode → 48kHz decode) and sample-rate conditioning, enabling native high-fidelity output without post-processing upsampling.
> See [VoxCPM 2 Model Details](https://voxcpm.readthedocs.io/en/dev_2.0/models/voxcpm2.html) for full architecture documentation and version changelog.
---
## ⚙️ Fine-tuning
VoxCPM supports both **full fine-tuning (SFT)** and **LoRA fine-tuning**. With as little as **5–10 minutes** of audio, you can adapt to a specific speaker, language, or domain.
# LoRA fine-tuning (parameter-efficient, recommended)
python scripts/train_voxcpm_finetune.py \
--config_path conf/voxcpm_v2/voxcpm_finetune_lora.yaml
# Full fine-tuning
python scripts/train_voxcpm_finetune.py \
--config_path conf/voxcpm_v2/voxcpm_finetune_all.yaml
# WebUI for training & inference
python lora_ft_webui.py # then open http://localhost:7860
```
> **Full guide →** [Fine-tuning Guide](https://voxcpm.readthedocs.io/en/dev_2.0/finetuning/finetune.html) (data preparation, configuration, training, LoRA hot-swapping, FAQ)
---
## 📚 Documentation
Full documentation: **[voxcpm.readthedocs.io](https://voxcpm.readthedocs.io/en/dev_2.0/)**
| Topic | Link |
|---|---|
| Quick Start & Installation | [Quick Start](https://voxcpm.readthedocs.io/en/dev_2.0/quickstart.html) |
| Usage Guide & Cookbook | [User Guide](https://voxcpm.readthedocs.io/en/dev_2.0/chefsguide.html) |
| VoxCPM Series | [Models](https://voxcpm.readthedocs.io/en/dev_2.0/models/voxcpm2.html) |
| Fine-tuning (SFT & LoRA) | [Fine-tuning Guide](https://voxcpm.readthedocs.io/en/dev_2.0/finetuning/finetune.html) |
| FAQ & Troubleshooting | [FAQ](https://voxcpm.readthedocs.io/en/dev_2.0/faq.html) |
---
## 🌟 Ecosystem & Community
| Project | Description |
|---|---|
| [**Nano-vLLM**](https://github.com/a710128/nanovllm-voxcpm) | High-throughput GPU serving |
| [**VoxCPM.cpp**](https://github.com/bluryar/VoxCPM.cpp) | GGML/GGUF: CPU, CUDA, Vulkan inference |
| [**VoxCPM-ONNX**](https://github.com/bluryar/VoxCPM-ONNX) | ONNX export for CPU inference |
| [**VoxCPMANE**](https://github.com/0seba/VoxCPMANE) | Apple Neural Engine backend |
| [**voxcpm_rs**](https://github.com/madushan1000/voxcpm_rs) | Rust re-implementation |
| [**ComfyUI-VoxCPM**](https://github.com/wildminder/ComfyUI-VoxCPM) | ComfyUI node-based workflows |
| [**ComfyUI-VoxCPMTTS**](https://github.com/1038lab/ComfyUI-VoxCPMTTS) | ComfyUI TTS extension |
| [**TTS WebUI**](https://github.com/rsxdalv/tts_webui_extension.vox_cpm) | Browser-based TTS extension |
> See the full [Ecosystem](https://voxcpm.readthedocs.io/en/dev_2.0/) in the docs. Community projects are not officially maintained by OpenBMB. Built something cool? [Open an issue or PR](https://github.com/OpenBMB/VoxCPM/issues) to add it!
---
## ⚠️ Risks and Limitations
- **Potential for Misuse:** VoxCPM's voice cloning can generate highly realistic synthetic speech. It is **strictly forbidden** to use VoxCPM for impersonation, fraud, or disinformation. We strongly recommend clearly marking any AI-generated content.
- **Technical Limitations:** The model may occasionally exhibit instability with very long or complex inputs. VoxCPM 2 introduces Voice Design and Style Control, though results may vary.
- **Language Coverage:** VoxCPM 2 supports 30 languages, but performance may vary depending on training data availability for each language.
- **Usage:** This model is released under the Apache-2.0 license. We do not recommend production use without rigorous testing and safety evaluation.
---
## 📚 Citation
If you find VoxCPM helpful, please consider citing our work and starring ⭐ the repository!
```bib
@article{voxcpm2025,
title = {VoxCPM: Tokenizer-Free TTS for Context-Aware Speech Generation
and True-to-Life Voice Cloning},
author = {Zhou, Yixuan and Zeng, Guoyang and Liu, Xin and Li, Xiang and
Yu, Renjie and Wang, Ziyang and Ye, Runchuan and Sun, Weiyue and
Gui, Jiancheng and Li, Kehan and Wu, Zhiyong and Liu, Zhiyuan},
journal = {arXiv preprint arXiv:2509.24650},
year = {2025},
}
```
## 📄 License
VoxCPM model weights and code are open-sourced under the [Apache-2.0](LICENSE) license.
## 🙏 Acknowledgments
- [DiTAR](https://arxiv.org/abs/2502.03930) for the diffusion autoregressive backbone
- [MiniCPM-4](https://github.com/OpenBMB/MiniCPM) for the language model foundation
- [CosyVoice](https://github.com/FunAudioLLM/CosyVoice) for the Flow Matching-based LocDiT implementation
- [DAC](https://github.com/descriptinc/descript-audio-codec) for the Audio VAE backbone
## Institutions
 ModelBest
ModelBest
 THUHCSI
THUHCSI
## ⭐ Star History
[](https://star-history.com/#OpenBMB/VoxCPM&Date)
{kind=link}
{kind=link}